VJBOD – E’ la possibilità di aumentare lo spazio del NAS connettendolo ad un’altro NAS – Sembra l’uovo di colombo, ma a volte si è in presenza di un NAS near-full e magari hai un’altro NAS in un’altra sede near-empty.. puoi connetterli assieme per scaricare il primo NAS. (fonte: https://www.youtube.com/watch?v=iEUJv-ke4dE https://www.youtube.com/watch?v=yNCqr5YlI8g )
MARS – E’ un’utility di backup che copia i dati da google foto (gia’ hai capito bene.. prima non si poteva fare) e li stora sul tuo nas.. e pensare che QNAP non la pubblicizza.. ovviamente gratuita con il NAS. (fonte: https://www.qnap.com/it-it/news/2022/la-miglior-soluzione-per-effettuare-il-backup-delle-foto-qnap-rilascia-la-soluzione-di-backup-di-google-foto-senza-limiti-di-capacit%C3%A0 )
Snapshot Vault/Replica – E’ la possibilità di copiare una snapshot effettuata dal un NAS Qnap verso un secondo NAS Qnap posto in un’altra locazione fisica. Mette il c..o a paratia (gergo militare) da errori umani e guasti e anche da virus. (fonte: https://www.qnap.com/en/how-to/tutorial/article/save-snapshots-to-other-qnap-nas-with-snapshot-replica)
Migrazione per guasto serio su un’altro NAS QNAP – In una vita puo’ capitare che un NAS smetta di funzionare per problemi non derivati da dischi o alimentatori, come ad esempio guasto sulla scheda madre e potrebbe essere conveniente acquistare un nuovo NAS.. con i QNAP è sufficiente migrare i dischi sul nuovo NAS QNAP e ripartire… puo’ sembrare una cosa da poco.. ma è una garanzia in ambiente industriale da non sottovalutare.. ( applicativo per migrazione https://www.qnap.com/it-it/nas-migration/ )
Boxafe – Backup di email e altro di Office 365 oppure Gmail Suite. Purtroppo a pagamento se su supera un cert numero di account. (fonte: https://www.youtube.com/watch?v=_TQQYVNFQUs )
Malware e Virus come evitare sorprese – Leggete questo articolo: https://www.qnap.com/solution/secure-storage/it-it/
Qualche tempo fa, mi è stato chiesto di implementare un sistema proxy in alta affidabilità da un mio cliente. Ho notato che in rete non c’e’ un howto per costruire un sistema del genere, allora ho pensato di scrivere qualche nota.
Elenco dei requisiti:
Il sistema proxy non deve avere delle licenze da pagare ne one-shot ne annualmente; insomma, deve essere gratis.
Deve servire circa 150 utenti possibilmente senza rallentamenti anche in caso di failover del primo nodo.
Non deve essere soggetto a sospensione del servizio dovuti a manutenzione (pianificati) o guasti (non pianificati).
Il sistema proxera’ le richieste solo se aderenti ai dati presenti su tre white-list a cura dal personale IT contenenti indirizzi IP, URL e domini.
Deve essere emessa una notifica in caso di down del nodo primario in modo che il personale IT sia a conoscenza che il sistema proxy sta funzionando in maniera degradata.
Il sistema si deve automaticamente ritornare sul nodo MASTER quando il problema su di esse è cessato.
In modalita’ normale sarebbe preferibile che il sistema processi le richieste in parallelo, bilanciando il carico tra le due macchine (active-active e non active-passive)
Briefing
Dunque, la prima cosa da decidere, il sistema operativo, gratis significa Linux o BSD.. io lavoro da circa vent’anni con Redhat (ora a pagamento) e quindi oggi lavoro con CentOS il quale è basato sugli stessi sorgenti. Non ho trovato in rete un vero HOW-TO sul come fare questo progetto, quindi ho deciso di scriverne uno, in italiano. Per il sistema proxy, non c’e’ tanto da pensare, il cliente ha gia’ le liste in formato testo adatte a squid, qundi direi che il sistema proxy è squid. Inoltre è un software che c’e’ da sempre (non so se sia nato prima Linux o prima squid) quindi è affidabile e soprattutto open-source. Per quanto riguarda le White-list basta montarle su una share di un file server per avere tre liste sempre aggiornate su entrambi i proxy. Poi mi sono pensato un trucchetto in caso il file server contenente le White-list non fosse disponibile in modo che gli squid continuino a funzionare, su White-list non aggiornate ma continuino ad andare (e si potrebbero anche aggiornare ogni tanto via script). Ora manca un modulo che mi permetta di avere una sorta di alta affidabilità: un modulo che in caso rilevi un problema possa migrare un indirizzo IP sulla macchina secondaria. Keepalived è la mia scelta. Il motivo è che ci ho gia’ lavorato e che mi piace per la sua semplicità. I nodi comunicano tra loro in Multicast e sembra che questo demone sia molto leggero per il sistema. Per fornire il servizio dei proxy active-active ho pensato che HAPROXY potrebbe fornirmi il necessario. L’idea è stata di mettere in ascolto HAPROXY su qualsiasi IP della macchina linux su porta 3128 porta classica di Squid, e inoltrare in modalità tcp le richieste ai due Squid presenti sulle due macchine, controllando che siano attivi via istruzione check effettuato da HAPROXY. Ovviamente ho dovuto modificare la porta di ascolto degli Squid. Quindi in modalità normale, ovvero quando tutto è correttamente funzionante, la macchina MASTER invia tramite HAPROXY le richieste dei client ad entrambi gli Squid in modaità round-robin che per le sessioni http sembra sia la migliore strategia.
Il sistema operativo
Lavoro da un mare di tempo con CentOS e non mi viene proprio voglia di cambiare, quindi i due nodi saranno due linux box con CentOS V7.5. Finita l’installazione io ho effettuato le seguenti personalizzazioni:
Disabilitato Selinux
Installato net-tools – Per avere ifconfig
Installato procps – Per avere killall che serve a keepalive
Disabilitato e rimosso dall’autostart Firewalld
Impostato in /etc/sysctl.conf la linea “net.ipv4.ip_nonlocal_bind = 1” che serve per ascoltare anche su ip che non esistono sulla macchina.
Keepalived
Ci sono diversi sistemi per avere una coppia di Linux box ad alta affidabilita’, ma io sono di quelli che “cavallo che vince non si cambia”: ho gia’ lavorato con keepalived e quindi implemento cio’ che conosco. Secondo me semplice come configurazione e si installa facilmente perché è di ‘serie’ su CentOS, ti basta fare:
vrrp_script chk_squid { script “/usr/bin/killall -0 squid” # verify the pid existance interval 2 # check every 2 seconds weight 2 # add 2 points of prio if OK }
vrrp_script chk_haproxy { script “/usr/bin/killall -0 haproxy” # verify the pid existance interval 2 # check every 2 seconds weight 2 # add 2 points of prio if OK }
vrrp_instance VI_1 { interface eth0 # interface to monitor state MASTER virtual_router_id 54 # Assign one ID for this route priority 101 # 101 on master, 100 on backup advert_int 1 smtp_alert virtual_ipaddress { 10.12.14.140 # the virtual IP } track_script { chk_squid chk_haproxy } }
In sostanza si vedono bene i due ‘vrrp_script’ che controllano che i due processi siano UP e il ‘vrrp_instance’ che è il cuore di keepalived. Questo è lo script del MASTER, quindi quando si sveglia si mette come MASTER e si autoassegna un priorita’. Si assegna un ‘router_id’ che serve al demone per comunicare con l’altro nodo via unicast. Inoltre quando deve operare perché qualcosa è andato storto (non vede l’altro nodo) ci avvisa via smtp. Il resto non credo che ci sia bisogno di spiegazioni. Allego anche lo script del secondo nodo per completezza:
vrrp_script chk_squid { script “/usr/bin/killall -0 squid” # verify the pid existance interval 2 # check every 2 seconds weight 2 # add 2 points of prio if OK }
vrrp_script chk_haproxy { script “/usr/bin/killall -0 haproxy” # verify the pid existance interval 2 # check every 2 seconds weight 2 # add 2 points of prio if OK }
vrrp_instance VI_1 { interface eth0 # interface to monitor state BACKUP virtual_router_id 54 # Assign one ID for this route priority 100 # 101 on master, 100 on backup advert_int 1 smtp_alert virtual_ipaddress { 10.12.14.140 # the virtual IP } track_script { chk_squid chk_haproxy } }
HAProxy
Il demone HAProxy è il responsabile per il bilanciamento di carico dei proxy Squid. Esso riceve le richieste dei client su porta 3128 (ho scelto questa porta in quanto tutti sono abituati al fatto che se c’e’ un proxy Squid questo ascolta su questa porta) e inoltra le sessioni sui proxy Squid attivi in quel momento. Il demone conosce il proxy attivo il quanto effettua un check su entrambi i proxy Squid in modo da esere a conoscenza su quale Squid inoltrare le richieste. Il demone HAProxy è in grado di inoltrare migliaia di sessioni senza avere problemi di performance, leggete la documentazione e i test che sono stati effettuati su questo software se siete curiosi. Allego i file di configurazione dei due HAProxy montati sulle due macchine linux: i due file sono uguale su entrambe le macchine linux. Precisiamo che in questo particolare caso ci limitamo ad avere ‘solo’ due proxy Squid, ma si potrebbe aggiungere altre macchine linux, queste con i solo demone Squid configurato, per avere un cluster con un parallelismo maggiore di due. Si potrebbe avere altre due macchine linux con Squid montato e utilizzare quattro Squid per servire i nostri utenti.
global daemon maxconn 256 defaults mode tcp timeout connect 5000ms timeout client 50000ms timeout server 50000ms
frontend squid_frontend bind *:3128
default_backend squid_backend backend squid_backend server node1 10.12.14.141:8001 check server node2 10.12.14.142:8001 check # Add more IPs here as required balance roundrobin
listen stats # Define a listen section called “stats” bind :9000 # Listen on localhost:9000 mode http stats enable # Enable stats page stats hide-version # Hide HAProxy version stats realm Haproxy\ Statistics # Title text for popup window stats uri /haproxy_stats # Stats URI stats auth amin:paperina # Authentication credentials
Squid
Proxy Squid. Squid è un proxy che conosciamo tutti: chi ha messo in pista una macchina proxy con linux lo ha fatto con Squid. E’ robusto, e’ mantenuto aggiornato, e’ gratis e funziona, non c’e’ bisogno di provare qualcosa d’altro. Nel nostro sistema proxy, viene usato molto semplicemente con delle white-list, c’e’ un minimo di configurazione da fare ma la cosa piu’ importate è il cambio di porta di ascolto, nel nostro caso da 3128 viene modificata in 8001. Poi c’e’ il discorso delle white-list ma non mi pare che sia un argomento da trattare.. non ci interessa l’autenticazione, ma anche qui si trova tutto in rete. Invece voglio dirvi come ho fatto a fare in modo che, se per caso la share che condivide le white-list non fosse disponibile ,il sistema comunque continui a funzionare. Ho semplicemente copiate le white-list interessate nella directory /mnt/wl – certo che nel momento del problema non saranno aggiornate, ma sempre meglio che rimanere senza che su un sistema che lavora in white list significa non navigare piu’ da nessuna parte… e poi si potrebbe fare in modo via script che ogni giorno venga smontata la share, copiate le whitelist e rimontata la share..
Conclusioni
Il sistema sta funzionando correttamente, per ora non sono stati riscontrati disservizi, purtroppo non è sottoposto ad un carico pesantissimo, i due nodi sfiorano carico ‘1’ negli ultimi 5 minuti solo all’inizio delle ore mattutine e pomeridiane
Questa procedura serve a guidare la sostituzione di due firewall Sonicwall in alta affidabilità resi obsoleti dal passare del tempo, con una coppia di firewall in alta affidabilità.
Si assume la nuova coppia sia gia’ stata registrata, provata e configurata con la configurazione della vecchia coppia di firewall.
Si assume che il cluster HA sia funzionante e a regime (Primario Attivo e Secondario Stand by)
Occorre avere a disposizione un pc portatile con interfaccia ethernet configurata su un ip compatibile con l’interfaccia di management del firewall (se di fascia NSa) il quale è di default configurato con l’ip 192.168.1.254/24
Etichettare tutti i cavi
Spegnere il vecchio secondario, che deve essere in STAND-BY ovviamente.
Smontare il vecchio secondario
Montare il nuovo primario al posto del vecchio secondario
Collegare i cavi al nuovo primario ma senza inserire sino a fondo le ethernet in modo che non siano collegate elettricamente ma pronte ad esserlo con una piccola pressione per minimizzare i tempi. L’interfaccia per l’alta disponibilità non deve essere collegata.
Accendere il nuovo primario che (ripeto) non dovra’ avere i cavi elettricamente connessi.
Attendere sino a che il nuovo primario sia pronto all’operativita’ (spie con la chiave inglese spente)
Spegnere il vecchio primario
Spingere le connessioni ethernet del nuovo primario in modo che siano elettricamente connesse.
Effettuare i primi test per verificare che tutto sia perfettamente funzionante.
Nota che l’interfaccia di alta disponibilità non è collegata.
NOTA BENE : In caso di problemi è sufficiente spegnere il nuovo primario ed accendere il vecchio primario per essere nella vecchia situazione sicuramente funzionante.
Se possibile lasciare questa configurazione per qualche giorno, in modo da essere perfettamente certi che il nuovo primario sia operativo esattamente come ci si aspetta.
Inserimento nuova unità secondaria
Per l’inserimento del nuovo secondario è sufficiente smontare il vecchio primario e al suo posto installare il nuovo secondario rispettando l’ordine delle interfacce ethernet. Ora è possibile collegare l’interfaccia di alta disponibilità. Accendere il nuovo secondario e aspettare. Il nuovo primario prenderà in carico il nuovo secondario, gli invierà la configurazione e lo farà ripartire.. dopo circa 10 minuti la pagina della gestione HA dovrebbe mostrare il primario attivo e il secondario in stand-by.
Oggi 7 gennaio 2026 ho iniziato l’aggiornamento del nostro Proxmox 8.4.16 all’ultima versione. Elenco i passi necessari che ho fatto per questo aggiornamento.
A macro step questi sono i passi:
Allineamento di tutti i nodi all’ultima versione di PVE nel mio caso 8.4.16
Aggiornamento di CEPH da versione Reef (V.18) a Squid (V.19) su tutti i nodi
Aggiornamento di tutti i nodi alla V9.1 di PVE
Aggiornamento di CEPH da Reef a Squid
Questo si fa abbastanza velocemente: è sufficiente modificare le sorgenti ceph con sed -i ‘s/reef/squid/’ /etc/apt/sources.list.d/ceph.list e impostare il flag noout: ceph osd set noout Seguito da: apt update apt full-upgrade
Ovviamente su tutti i nodi. Il flag di noout deve restare cosi’ sino alla fine dell’aggiornamento.
Aggiornamento da PVE V.8.4.16 a V9.1
Successivamente quando tutti i nodi sono su CEPH Squid si modificano le sorgenti APT in che da bookworm si modifica in trixie con un comando sed:
sed -i ‘s/bookworm/trixie/g’ /etc/apt/sources.list sed -i ‘s/bookworm/trixie/g’ /etc/apt/sources.list.d/pve-no-subscription.list sed -i ‘s/bookworm/trixie/g’ /etc/apt/sources.list.d/pve-enterprise.list sed -i ‘s/bookworm/trixie/g’ /etc/apt/sources.list.d/pve-enterprise.list sed -i ‘s/bookworm/trixie/g’ /etc/apt/sources.list.d/ceph.list Per verifica poi fa un: grep -R “trixie” /etc/apt/sources.list /etc/apt/sources.list.d dovresti vedere un bel po’ di file che matchano e poi un grep -R “book” /etc/apt/sources.list /etc/apt/sources.list.d e non dovrebbe darti nessun risultato Ora puoi procedere con: apt update Seguito da: apt dist-upgrade e poi un ‘reboot’ Ovviamente su tutti i nodi. Quando hai finito dovresti avere solo da togliere il flag noout, basta che lo fai su un nodo ceph osd unset noout
Non installate questo software a meno che non vogliate installare anche il provider di autenticazione keyclock. Secondo me è molto meglio usare nextcloud che gestisce normalmente l’autenticazione doppio fattore TOTP. Lasciate perdere ‘sto coso’.
Vai sul server DHCP che vuoi mantenere in vita, click con il destro sullo scope interessato e fai ‘Deconfigure Failover’. Questo cancella lo scope ‘dal server parner’ e rimuove la relazione.
Poi vai su IPV4 e properities e vai sul tab “Failover” e premi ‘Delete’. Questo rimuove la relazione tra i due server.
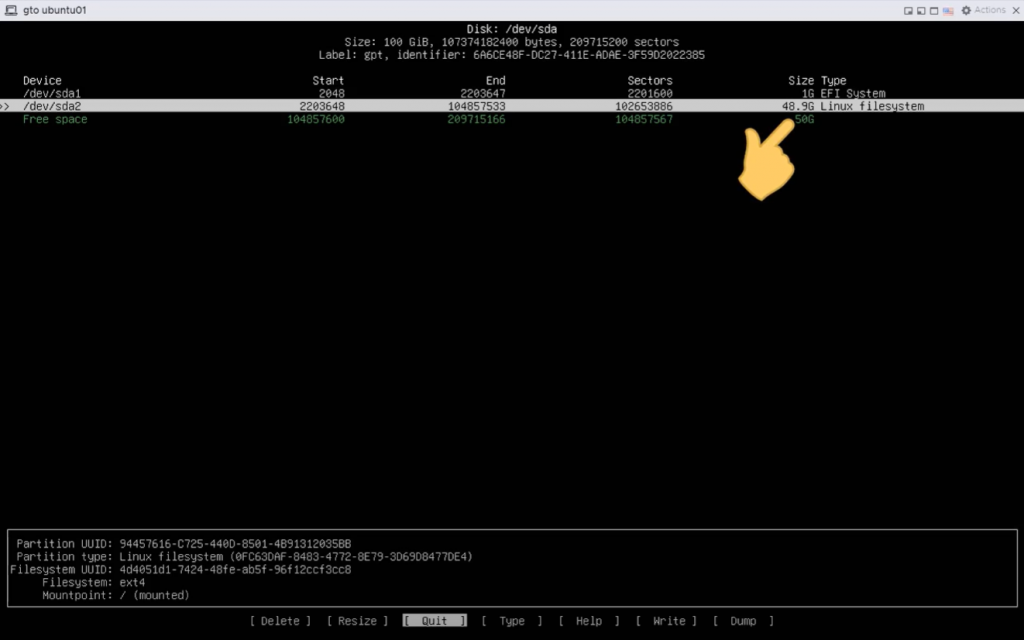
Questo si applica quando abbiamo un utente, anche AD, che deve accedere in full control ad una cartella che è posizionata dentro ad una cartella in read-only per lui.
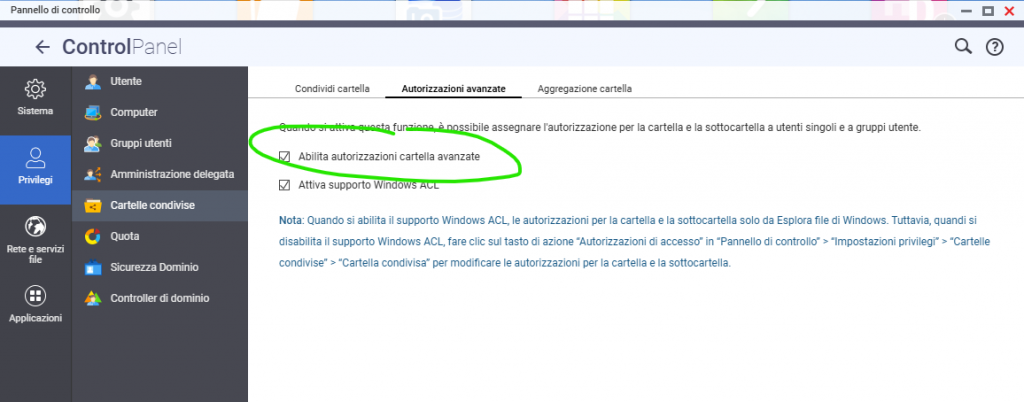
Occorre abilitare le “autorizzazione avanzate” come in figura
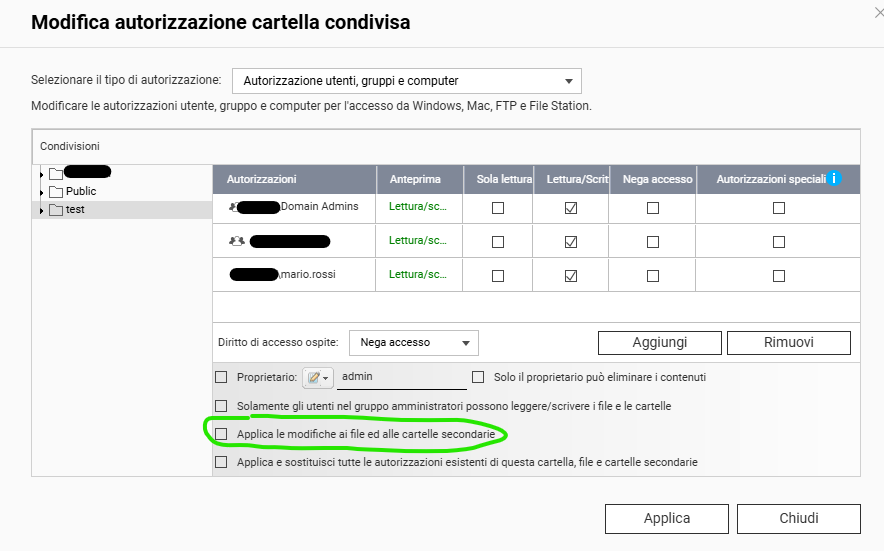
Poi nella GUI di Qnap nelle cartelle condivise dare accesso all’utente, come in figura togliendo “Applica le modifiche ai file e alle cartelle secondarie” per ovvi motivi.
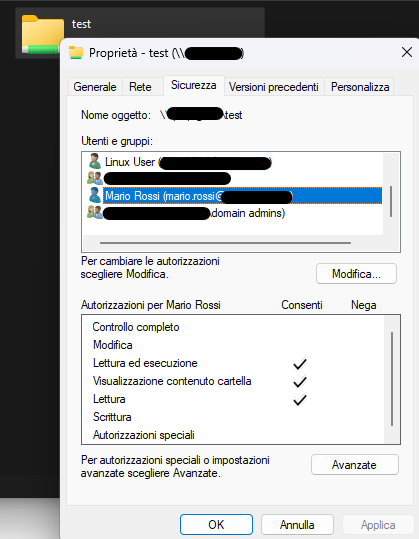
successivamente via windows dare i permessi come segue per le cartelle ‘read only’:
Dare ‘Full Control’ alle cartelle che Mario Rossi deve avere il pieno accesso.
Se hai installato un vcsa8 piu’ o meno di default, la sacdenza delle password e’ impostata a 90 giorni. Siccome di solito le cose vanno nel verso giusto (almeno nei primi 90 giorni) potrebbe capitare che un giorno entri nel vcenter e vedi un paio di errori del tipo “la password di root e’ in scadenza” in giallo e un’altro in rosso “La password di root e’ scaduta”. In realta’ non c’e’ nulla che non funzioni, ma se provi ad entrare nella console del vcsa, quella su porta 5480 per capirci, ti da un errore del genere “Exception in invoking authentication handler user password expired”.
Meno male che risolvere e’ una minchiata: entri in ssh sull’ip del vcsa con la vecchia password.. ci pensa un po’ e poi lui stesso si rende conto che sta dicendo una minchiata e ti dice che la passeword di root e’ scaduta, ti chiede la vecchia password e ti fa inserire la nuova, due vole come al solito. A questo punto puoi entrare nella parte web e correre e cambiare la scadenza da “90 giorni” a “mai”.