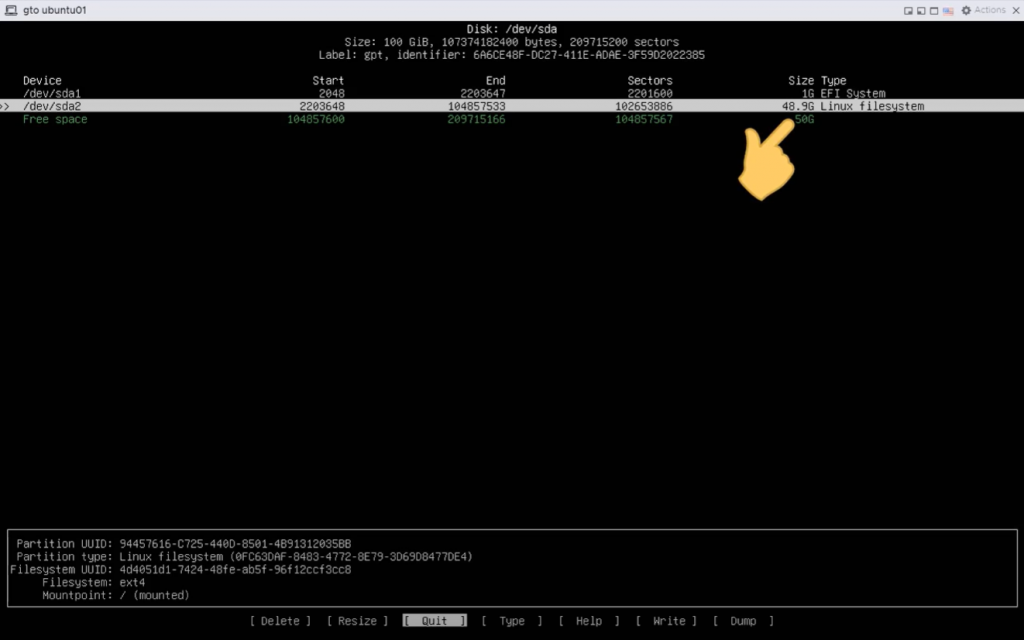
La piattaforma Wazuh offre funzionalità XDR e SIEM per proteggere i carichi di lavoro cloud, container e server. Queste includono l’analisi dei dati di log, il rilevamento di intrusioni e malware, il monitoraggio dell’integrità dei file, la valutazione della configurazione, il rilevamento delle vulnerabilità e il supporto per la conformità normativa.
La soluzione Wazuh si basa sull’agente Wazuh, che viene distribuito sugli endpoint monitorati, e su tre componenti centrali: il server Wazuh, l’indicizzatore Wazuh e la dashboard Wazuh.
- L’ indicizzatore di Wazuh è un motore di ricerca e analisi full-text altamente scalabile. Questo componente centrale indicizza e memorizza gli avvisi generati dal server Wazuh.
- Il server Wazuh analizza i dati ricevuti dagli agenti. Li elabora tramite decodificatori e regole, utilizzando l’intelligence sulle minacce per individuare i noti indicatori di compromissione (IOC). Un singolo server può analizzare i dati provenienti da centinaia o migliaia di agenti e scalare orizzontalmente se configurato in cluster. Questo componente centrale viene utilizzato anche per gestire gli agenti, configurandoli e aggiornandoli da remoto quando necessario.
- La dashboard di Wazuh è l’interfaccia utente web per la visualizzazione e l’analisi dei dati. Include dashboard predefinite per la ricerca di minacce, la conformità normativa (ad esempio, PCI DSS, GDPR, CIS, HIPAA, NIST 800-53), le applicazioni vulnerabili rilevate, i dati di monitoraggio dell’integrità dei file, i risultati della valutazione della configurazione, gli eventi di monitoraggio dell’infrastruttura cloud e altro ancora. Viene inoltre utilizzata per gestire la configurazione di Wazuh e per monitorarne lo stato.
- Gli agenti Wazuh vengono installati su endpoint quali laptop, computer desktop, server, istanze cloud o macchine virtuali. Forniscono funzionalità di prevenzione, rilevamento e risposta alle minacce. Sono compatibili con sistemi operativi come Linux, Windows, macOS, Solaris, AIX e HP-UX.
Oltre alle funzionalità di monitoraggio basate su agenti, la piattaforma Wazuh è in grado di monitorare dispositivi senza agenti come firewall, switch, router o IDS di rete, tra gli altri. Ad esempio, i dati di log di un sistema possono essere raccolti tramite Syslog e la sua configurazione può essere monitorata tramite interrogazioni periodiche dei dati, via SSH o tramite API.